Tidb
Architecture
01.LSM-Tree与RocksDB
02.TiDB 构架
03.TiDB 架构演进
PD
TiKV
TiFlash
TiProxy
Installation and Deployment
Tidb 敏捷模式部署
Data Migration and Validation
Backup and Recovery
Command-Line Tool
Optimization and Adjustment
如何通过调整`split-region-size`参数来动态优化Region分裂阈值?
本文档使用 MrDoc 发布
-
+
首页
01.LSM-Tree与RocksDB
# 1. LSM-Tree基础概述 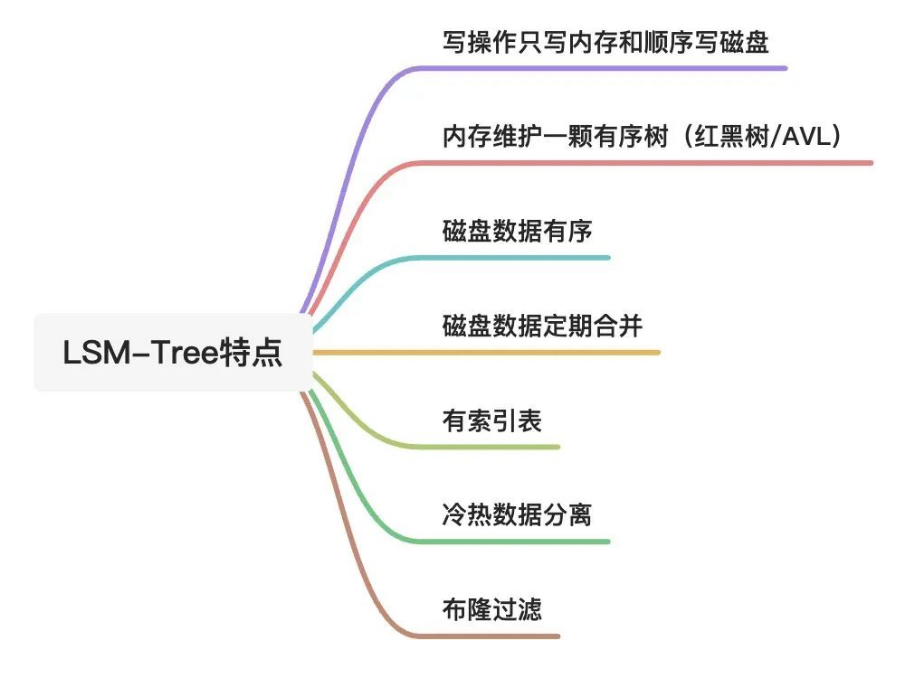 ## 1.1 概念与起源 `LSM-Tree 数据在磁盘中的组织方式。LSM 树结构的问题: 写入速度快,读取速度慢,写放大和读放大都较高。` LSM-Tree的概念出自1996年的一篇论文,它提出了针对存储排序文件过程中合并和压缩的算法。之后基于该原则的存储引擎通常被称为LSM存储引擎。 如果持久型数据库存入数据时,需要随机写入磁盘,需要寻找对应的磁盘位置,包括寻找磁道、扇区,转动磁头。转动磁头这一机械过程相对于数据写入的其他过程(CPU的计算和磁头电流改变磁盘单元格的磁场)是非常缓慢的,这是高速I/O的瓶颈所在。 LSM-Tree的思想是:借助于内存和日志文件将写入过程分为时间上不前后相连的两步,写入时只顺序写入磁盘的日志文件和内存,等系统空闲时再将内存中数据写入到磁盘。这样在处理写入请求时就省去了磁盘寻道、转动磁头的时间。 2006年,Google发表了BigTable的论文。LSM-Tree是Google BigTable和HBase的基本存储算法,它是传统关系型数据库B+树的改进。`算法的关注重心是 “如何在频繁的数据改动下保持系统读取速度的稳定性”,算法的核心在于尽量保证数据是顺序存储到磁盘上的,并且会有频繁地对数据进行整理,保证其顺序性。而顺序性就可以最大程度保证数据的读取性能稳定。` 目前,LSM被很多存储产品作为存储结构,比如Apache HBase、Apache Cassandra、MongoDB的Wired Tiger存储引擎、LevelDB存储引擎、RocksDB存储引擎等。简单地说,LSM的设计目标是提供比传统的B+树更好的写性能。`LSM 通过将磁盘的随机写转化为顺序写来提高写性能 ,而付出的代价就是牺牲部分读性能、写放大(B+树同样有写放大的问题)。`LSM相比B+树能提高写性能的本质原因是:外存的随机读写都要慢于顺序读写,无论磁盘还是SSD。 ## 1.2 核心设计思想 LSM-Tree的核心是“延迟合并,优先写内存”,本质是通过牺牲部分读能力换取最大化写入性能,具体逻辑如下: - 所有写入(插入、更新、删除)先暂存于内存,避免直接操作磁盘带来的寻道开销; - 当内存数据达到阈值时,批量顺序写入磁盘,并与已有磁盘数据异步合并; - 合并时不修改原数据,直接写入新数据,彻底规避磁盘随机写,同时通过后台合并保持数据顺序性,保障读取性能稳定。 LSM-Tree能提升写性能的本质是:外存(磁盘、SSD)的顺序读写速度远优于随机读写,其核心逻辑可概括为“先内存缓存,后磁盘分层合并”。 ## 1.3 核心结构与组件 LSM-Tree横跨内存与磁盘,由4个关键组件构成,确保数据可靠性与读写效率,各组件详情如下表: | 组件名称 | 存储位置 | 核心作用 | 特性 | | ----------------------- | -------- | ------------------------------------------------------------ | ------------------------------------------------------------ | | Memtable(内存可变表) | 内存 | 接收最新写入操作,保持数据有序(常用跳表、红黑树实现) | 支持读写,性能高;需配合WAL防止内存掉电丢失数据 | | Immutable Memtable | 内存 | Memtable达到阈值后转为“不可变”,作为刷盘前的中间状态 | 只读,不阻塞新写入(新写入由新Memtable承接),避免写操作等待 | | SSTable(有序字符串表) | 磁盘 | 存储Immutable Memtable刷盘后的数据,按key有序排列,是磁盘层的核心结构 | 只读不可改,可建立索引加速查询;多个SSTable按生成时间/层级组织 | | WAL(预写日志) | 磁盘 | 写入Memtable前先顺序写入WAL,记录数据变更 | 顺序写,确保Memtable数据丢失时可恢复,保障数据持久性 | 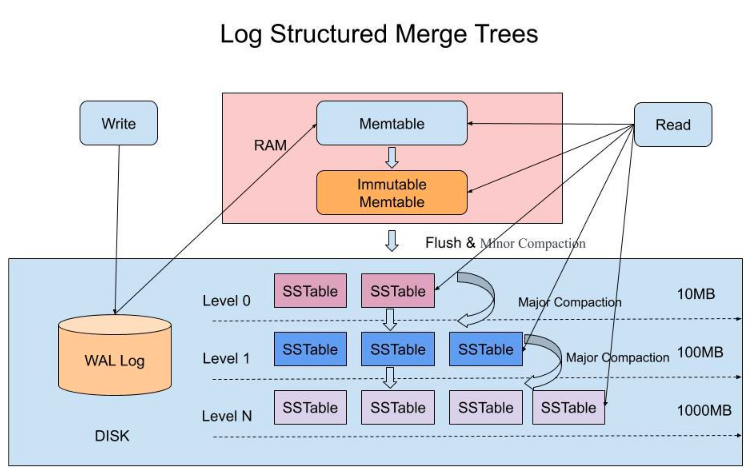 ## 1.4 读写与合并流程 ### 1.4.1 数据写入流程 1. **日志预写(WAL)**:数据写入时先写入Write Ahead Log,确保崩溃后数据可恢复,避免丢失; 2. **内存缓存(MemTable)**:同时将数据写入内存中的MemTable(常用跳表实现),依托内存高读写速度保障写入吞吐量; 3. **内存刷盘(Flush)**:当MemTable达到阈值(如TiKV中默认128MB),转为只读的Immutable Memtable,后台线程将其按键有序排列,刷写到磁盘生成SSTable,存入最底层(L0); 4. **分层合并(Compaction)**:当某一层SSTable数量或总大小达到阈值,后台线程将其与下一层SSTable合并,删除过期数据与冗余记录,保持各层数据有序且键范围不重叠(L0除外)。 ### 1.4.2 数据读取流程 读取时按“内存→最新磁盘→旧磁盘”的顺序查找:首先在Memtable中查找key,再查询最新的磁盘SSTable文件,依次遍历至次新文件,直至找到目标或确定为空。为优化不存在key的查询效率,引入布隆过滤器,可快速返回不存在结果,避免无效磁盘扫描。 ### 1.4.3 Compaction合并策略 合并操作是LSM-Tree平衡性能的核心,用于解决数据冗余与查询效率问题,核心策略有两种: - **Size-tiered策略**:当某层级SSTable数量达到阈值,按大小分组合并为更大的SSTable写入下一层,减少文件数量,降低查询时的磁盘扫描次数; - **Leveled策略**:每一层SSTable总大小为前一层的固定倍数(默认10倍),L0合并后写入L1,L1达到阈值后合并写入L2,依次类推,同一层级SSTable键范围不重叠,降低读放大与空间放大。 ## 1.5 性能优化手段 - **BlockCache**:内存缓存磁盘SSTable的数据块(默认64KB),按LRU算法淘汰,TiKV默认分配系统内存的45%给BlockCache,减少磁盘IO; - **Bloom Filter**:嵌入SSTable中,快速过滤不存在的键,避免无效磁盘查询; - **多压缩支持**:可选LZ4、Snappy等压缩算法,平衡存储占用与压缩/解压性能; - **异步预取**:支持多扫描迭代器异步预取数据,优化Level迭代器性能(v10.9.1版本新增)。 # 2. 基于LSM-Tree的实现 目前基于LSM实现的数据库有:LevelDB,RocksDB,HBase,Cassandra,ClickHouse等。 ## 2.1 Google LevelDB 开源仓库:[https://github.com/google/leveldb](https://github.com/google/leveldb) LevelDB是由Google的工程师Jeff Dean和Sanjay Ghemawat开发的一个可持久化存储的KV数据库。LevelDB在普通的LSM-Tree架构的基础上进行了扩展,使其性能更佳,具体扩展如下: 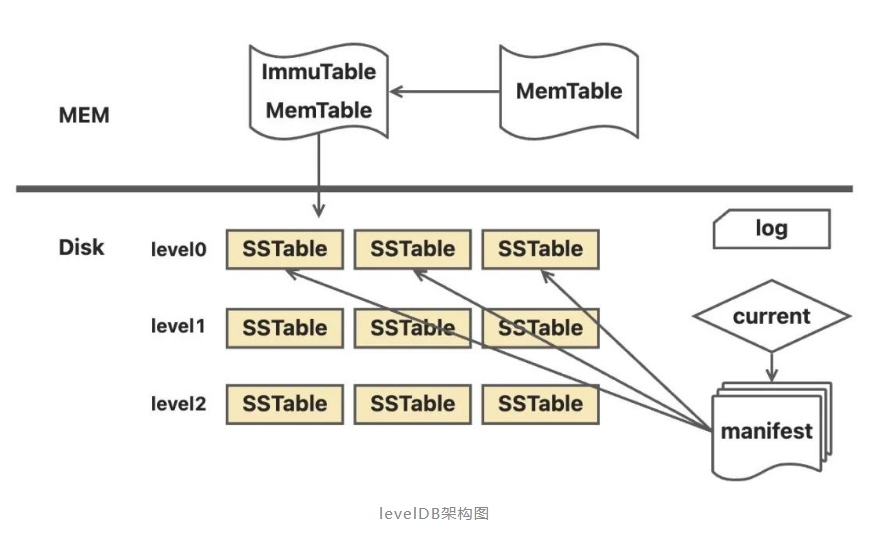 1. 内存中扩展了Immutable Memtable:目的是防止MemTable写入磁盘时系统无法对外提供服务,引入Immutable Memtable后,MemTable数据满时变为Immutable Memtable,由新的内存区域充当MemTable,这样MemTable便可以不间断地对外提供服务,Immutable Memtable在合适时机写入磁盘; 2. 对磁盘中的SSTable采用冷热数据的思想进行分级:等级越高的SSTable数据越新,查询时从等级高的数据开始查询(level0>level1>level2...); 3. 增加了manifest文件:manifest文件中记录了各Level中SSTable的分布、单个SSTable的最大最小key,以及其他LevelDB所需的元数据,便于查找时进行过滤; 4. 增加current文件:manifest随着不断合并可能会有多个,current文件的作用是记录最新的manifest文件位置。 (注:原图片无法加载,保留结构占位) LevelDB扩展完善了LSM-Tree的合并过程,采用多种压缩策略对不同场景下的SSTable进行合并,三种压缩策略如下表: | 压缩策略 | 描述 | | ---------------- | ------------------------------------------ | | minor Compaction | 把MemTable中的数据导入到SSTable | | major Compaction | 合并不同层级的SSTable文件,减少Level的数量 | | full Compaction | 将所有的SSTable文件合并 | LevelDB中实现了minor compaction和major compaction,其中major compaction由以下三种方式触发: | 触发方式 | 描述 | | ---------------- | ------------------------------------------------------------ | | size compaction | 平衡操作,当系统发现某一层的SSTable数量超过阈值的时候会触发compaction | | manul compaction | 人工手动触发,通过接口调用人为地去触发它执行Compaction | | seek compaction | 记录每一个SSTable文件的不命中率,当某个SSTable的不命中率达到阈值时,会将其合并到下一层的Level中 | (注:原图片无法加载,保留结构占位) ## 2.2 HBase 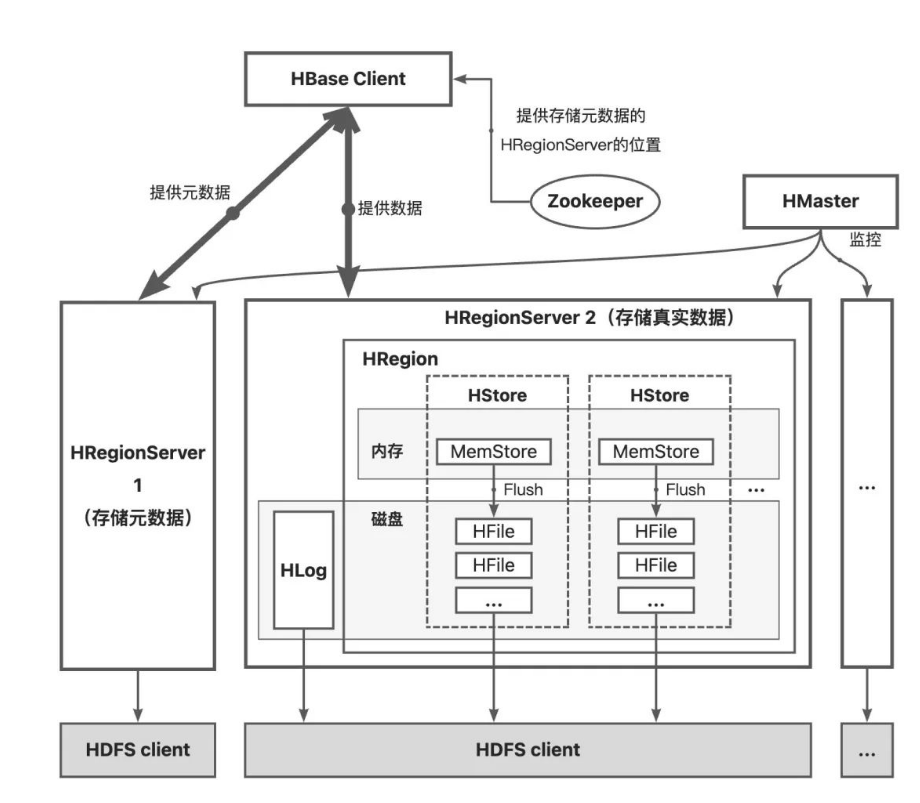 HBase的HStore基于LSM-Tree思想实现,核心分为MemStore(内存层)和HFile(磁盘层): - MemStore:位于内存,维护有序数据结构,接收新写入数据; - HFile:磁盘存储核心,MemStore达到阈值后刷盘生成HFile,多个HFile积累到一定数量后触发合并,清理冗余数据,保持有序性。 (注:原图片无法加载,保留结构占位) ## 2.3 ClickHouse ClickHouse的Merge引擎采用LSM-Tree思想,强化了索引设计,提升了查询性能,核心流程如下: ### 2.3.1 数据写入过程 数据先写入内存缓冲区(阈值可配置,默认64KB~1MB),达到阈值后压缩排序写入磁盘,生成新分区。每个分区包含校验文件、索引文件、偏移文件、数据文件: - 校验文件:校验分区内数据完整性; - 索引文件:快速定位目标数据; - 偏移文件:标记数据在分区压缩块中的偏移位置; - 数据文件:由多个压缩块组成,存储核心数据。 ### 2.3.2 分区合并过程 ClickHouse定期合并partition值相同的分区,结合索引文件与偏移文件,按归并思想合并数据,生成新分区,同时合并对应索引、偏移等辅助文件,保持数据有序性。 ## 2.4 RocksDB深度解析 相关资源: - 开源仓库:[https://github.com/facebook/rocksdb/releases/tag/v10.9.1](https://github.com/facebook/rocksdb/releases/tag/v10.9.1) - B站讲解视频:[https://www.bilibili.com/video/BV1W3411s7uu/](https://www.bilibili.com/video/BV1W3411s7uu/?spm_id_from=333.337.search-card.all.click&vd_source=05b2ffb7879be635c75c1bc8bfc3eb13) - TiDB对RocksDB的概述:[https://docs.pingcap.com/zh/tidbcloud/rocksdb-overview/](https://docs.pingcap.com/zh/tidbcloud/rocksdb-overview/) - 延伸阅读:[OceanBase数据库LSM-Tree存储引擎深度解析](https://open.oceanbase.com/blog/21146957168) 2012年,Meta(原Facebook)推出了高性能、可扩展的嵌入式键值存储数据库RocksDB,其存储引擎采用LSM-Tree数据结构,重点优化写入密集型应用场景。RocksDB是Facebook开源的持久化KV存储引擎,最初由其数据库工程团队基于Google LevelDB开发。虽然很少有项目直接使用RocksDB存储数据,未来也难像Redis那样被业务系统直接采用,但它已成为越来越多新一代数据库的底层存储引擎选择。 RocksDB支持SSD、HDD等多种存储介质,提供丰富配置选项以适配不同工作负载,具备高吞吐量、低延迟特性,适合处理大规模数据的应用(如实时分析、运营智能、机器学习),同时支持列族(Column Family)、压缩、缓存、WAL(预写日志)等能力,进一步提升性能与可靠性。 值得一提的是,Meta毫不避讳RocksDB是站在Google LevelDB、Apache HBase等巨人肩膀上演变而来。对比国内部分公司刻意强调“纯自研”“根自研”的态度,这种开放包容的理念更利于技术迭代,也期待国产数据库能以更自信的姿态正视技术传承与创新。 RocksDB的读写核心流程遵循LSM-Tree思想,具体实现如下: 1. 写入WAL日志:所有写入操作先写入WAL日志(可选关闭以提升性能,但会面临崩溃丢数据风险),再写入内存MemTable; 2. MemTable存储:MemTable默认采用支持并发写入的跳表实现,同时提供多种跳表类型供用户根据业务场景选择; 3. MemTable刷盘:当MemTable写满后,转为只读的Immutable Memtable,后台flush线程将其刷盘生成SSTable文件,存入Level 0层; 4. 分层合并:当Level 0层SST文件数量超过阈值,通过Compaction策略将其合并至Level 1层,依次向下迭代,保持各层数据有序性。 # 3. RocksDB解决的具体问题 RocksDB已成为多款数据库与存储系统的核心引擎,针对性解决传统引擎痛点,典型应用场景如下: 1. MyRocks:MySQL的存储引擎替代 - 场景:高写入压力的MySQL实例; - 价值:替换InnoDB的B+树结构,将随机写转化为顺序写,提升写入吞吐量,同时减少磁盘IO与存储占用。 2. Pika:Redis的替代方案 - 场景:海量键值存储,需降低内存成本; - 价值:基于RocksDB实现持久化存储,兼容Redis协议,突破内存容量限制,同时保持高写入性能。 3. TiKV:TiDB的分布式存储引擎 - 场景:分布式数据库的底层数据存储(含Raft日志与用户数据); - 实现:TiKV包含两个RocksDB实例——raftdb(存储Raft日志)与kvdb(存储用户数据与MVCC元数据),kvdb通过4个列族(CF)分别存储元数据、锁信息、短数据与长数据,适配分布式事务与多版本控制需求。 > (注:文档部分内容可能由 AI 生成)
Seven
2026年1月18日 00:24
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码